Northwind
----------
http://www.4shared.com/file/71580360/c9e94375/instnwnd.html
Pubs
-----
http://www.4shared.com/file/71579808/62655b7b/instpubs.html
Monday, September 15, 2008
Cursors
SQL Server is very good at handling sets of data. For example, you can use a single UPDATE statement to update many rows of data. There are times when you want to loop through a series of rows a perform processing for each row. In this case you can use a cursor.
Please note that cursors are the SLOWEST way to access data inside SQL Server. The should only be used when you truly need to access one row at a time. The only reason I can think of for that is to call a stored procedure on each row.
The basic syntax of a cursor is:
--------------------------------
----------------------------------------------------------------------------------
DECLARE @AuthorID char(11) DECLARE c1 CURSOR READ_ONLYFORSELECT au_idFROM authorsOPEN c1FETCH NEXT FROM c1INTO @AuthorIDWHILE @@FETCH_STATUS = 0BEGIN PRINT @AuthorID FETCH NEXT FROM c1 INTO @AuthorIDENDCLOSE c1DEALLOCATE c1
-----------------------------------------------------------------------------------
The DECLARE CURSOR statement defines the SELECT statement that forms the basis of the cursor. You can do just about anything here that you can do in a SELECT statement. The OPEN statement statement executes the SELECT statement and populates the result set. The FETCH statement returns a row from the result set into the variable. You can select multiple columns and return them into multiple variables. The variable @@FETCH_STATUS is used to determine if there are any more rows. It will contain 0 as long as there are more rows. We use a WHILE loop to move through each row of the result set.
The READ_ONLY clause is important in the code sample above. That dramatically improves the performance of the cursor.
In this example, I just print the contents of the variable. You can execute any type of statement you wish here. In a recent script I wrote I used a cursor to move through the rows in a table and call a stored procedure for each row passing it the primary key. Given that cursors are not very fast and calling a stored procedure for each row in a table is also very slow, my script was a resource hog. However, the stored procedure I was calling was written by the software vendor and was a very easy solution to my problem. In this case, I might have something like this:
EXEC spUpdateAuthor (@AuthorID)
instead of my Print statement. The CLOSE statement releases the row set and the DEALLOCATE statement releases the resources associated with a cursor.
If you are going to update the rows as you go through them, you can use the UPDATE clause when you declare a cursor. You'll also have to remove the READ_ONLY clause from above.
----------------------------------------------------------------------------
DECLARE c1 CURSOR FORSELECT au_id, au_lnameFROM authorsFOR UPDATE OF au_lname
----------------------------------------------------------------------------
You can code your UPDATE statement to update the current row in the cursor like this
---------------------------------
UPDATE authors
SET au_lname = UPPER(Smith)
WHERE CURRENT OF c1
----------------------------------
-------------------------------------------------------------------------
http://www.sqlteam.com/article/cursors-an-overview
Please note that cursors are the SLOWEST way to access data inside SQL Server. The should only be used when you truly need to access one row at a time. The only reason I can think of for that is to call a stored procedure on each row.
The basic syntax of a cursor is:
--------------------------------
----------------------------------------------------------------------------------
DECLARE @AuthorID char(11) DECLARE c1 CURSOR READ_ONLYFORSELECT au_idFROM authorsOPEN c1FETCH NEXT FROM c1INTO @AuthorIDWHILE @@FETCH_STATUS = 0BEGIN PRINT @AuthorID FETCH NEXT FROM c1 INTO @AuthorIDENDCLOSE c1DEALLOCATE c1
-----------------------------------------------------------------------------------
The DECLARE CURSOR statement defines the SELECT statement that forms the basis of the cursor. You can do just about anything here that you can do in a SELECT statement. The OPEN statement statement executes the SELECT statement and populates the result set. The FETCH statement returns a row from the result set into the variable. You can select multiple columns and return them into multiple variables. The variable @@FETCH_STATUS is used to determine if there are any more rows. It will contain 0 as long as there are more rows. We use a WHILE loop to move through each row of the result set.
The READ_ONLY clause is important in the code sample above. That dramatically improves the performance of the cursor.
In this example, I just print the contents of the variable. You can execute any type of statement you wish here. In a recent script I wrote I used a cursor to move through the rows in a table and call a stored procedure for each row passing it the primary key. Given that cursors are not very fast and calling a stored procedure for each row in a table is also very slow, my script was a resource hog. However, the stored procedure I was calling was written by the software vendor and was a very easy solution to my problem. In this case, I might have something like this:
EXEC spUpdateAuthor (@AuthorID)
instead of my Print statement. The CLOSE statement releases the row set and the DEALLOCATE statement releases the resources associated with a cursor.
If you are going to update the rows as you go through them, you can use the UPDATE clause when you declare a cursor. You'll also have to remove the READ_ONLY clause from above.
----------------------------------------------------------------------------
DECLARE c1 CURSOR FORSELECT au_id, au_lnameFROM authorsFOR UPDATE OF au_lname
----------------------------------------------------------------------------
You can code your UPDATE statement to update the current row in the cursor like this
---------------------------------
UPDATE authors
SET au_lname = UPPER(Smith)
WHERE CURRENT OF c1
----------------------------------
-------------------------------------------------------------------------
http://www.sqlteam.com/article/cursors-an-overview
Monday, September 8, 2008
what is Surrogate Keys ?
the following articale from this link
http://decipherinfosys.wordpress.com/2007/02/01/surrogate-keys-vs-natural-keys-for-primary-key/
Surrogate Keys vs Natural Keys for Primary Key?
This topic probably is one of those that you cannot get any two database developers/DBAs to agree upon. Everyone has their own opinion about this and it is also one of the most discussed topics over the web when it comes to data modeling. Rather than taking any side :-), we are just listing out our experiences when it comes to chosing between a surrogate key vs the natural keys for the tables.0
Surrogate Key:
Surrogate keys are keys that have no “business” meaning and are solely used to identify a record in the table. Such keys are either database generated (example: Identity in SQL Server, Sequence in Oracle, Sequence/Identity in DB2 UDB etc.) or system generated values (like generated via a table in the schema).
Natural Key:
Keys are natural if the attribute it represents is used for identification independently of the database schema. What this basically means is that the keys are natural if people use them example: Invoice-Numbers, Tax-Ids, SSN etc.
Design considerations for choosing the Primary Key:
Primary Key should meet the following requirements:
- It should be not null, Unique and should apply to all rows.
- It should be minimal (i.e. less number of columns in the PK: ideally it should be 1, if using composite keys, then make sure that those are surrogates and using integer family data-types).
- It should be stable over a period of time (should not change i.e. update to the PK columns should not happen).
Keeping these in mind, here are the pros and cons of Surrogate vs. Natural keys:
Surrogate Key
I prefer surrogate keys to be DB controlled rather than being controlled via a next-up table in the schema since that is a more scalable approach.
Pros:
- Business Logic is not in the keys.
- Small 4-byte key (the surrogate key will most likely be an integer and SQL Server for example requires only 4 bytes to store it, if a bigint, then 8 bytes).
- Joins are very fast.
- No locking contentions because of unique constraint (this refers to the waits that get developed when two sessions are trying to insert the same unique business key) as the surrogates get generated by the DB and are cached - very scalable.
Cons:
- An additional index is needed. In SQL Server, the PK constraint will always creates a unique index, in Oracle, if an index already exists, PK creation will use that index for uniqueness enforcement (not a con in Oracle).
- Cannot be used as a search key.
- If it is database controlled, for products that support multiple databases, different implementations are needed, example: identity in SS2k, before triggers and sequences in Oracle, identity/sequence in DB2 UDB.
- Always requires a join when browsing the child table(s).
Natural Key
Pros:
- No additional Index.
- Can be used as a search key.
Cons:
- If not chosen wisely (business meaning in the key(s)), then over a period of time additions may be required to the PK and modifications to the PK can occur.
- If using strings, joins are a bit slower as compared to the int data-type joins, storage is more as well. Since storage is more, less data-values get stored per index page. Also, reading strings is a two step process in some RDBMS: one to get the actual length of the string and second to actually perform the read operation to get the value.
- Locking contentions can arise if using application driven generation mechanism for the key.
- Can’t enter a record until value is known since the value has some meaning.
Choosing Surrogate vs. Natural Keys:
There is no rule of thumb in this case. It has to be evaluated table by table:
- If we can identify an appropriate natural key that meets the three criteria for it to be a PK column, we should use it. Look-up tables and configuration tables are typically ok.
- Data-Type for the PK: the smaller the better, choose an integer or a short-character data type. It also ensures that the joins will be faster. This becomes even more important if you are going to make the PK as a clustered index since non-clustered indexes are built off the clustered index. RDBMS processes integer data values faster than the character data values because it converts characters to ASCII equivalent values before processing, which is an extra step.
http://decipherinfosys.wordpress.com/2007/02/01/surrogate-keys-vs-natural-keys-for-primary-key/
Surrogate Keys vs Natural Keys for Primary Key?
This topic probably is one of those that you cannot get any two database developers/DBAs to agree upon. Everyone has their own opinion about this and it is also one of the most discussed topics over the web when it comes to data modeling. Rather than taking any side :-), we are just listing out our experiences when it comes to chosing between a surrogate key vs the natural keys for the tables.0
Surrogate Key:
Surrogate keys are keys that have no “business” meaning and are solely used to identify a record in the table. Such keys are either database generated (example: Identity in SQL Server, Sequence in Oracle, Sequence/Identity in DB2 UDB etc.) or system generated values (like generated via a table in the schema).
Natural Key:
Keys are natural if the attribute it represents is used for identification independently of the database schema. What this basically means is that the keys are natural if people use them example: Invoice-Numbers, Tax-Ids, SSN etc.
Design considerations for choosing the Primary Key:
Primary Key should meet the following requirements:
- It should be not null, Unique and should apply to all rows.
- It should be minimal (i.e. less number of columns in the PK: ideally it should be 1, if using composite keys, then make sure that those are surrogates and using integer family data-types).
- It should be stable over a period of time (should not change i.e. update to the PK columns should not happen).
Keeping these in mind, here are the pros and cons of Surrogate vs. Natural keys:
Surrogate Key
I prefer surrogate keys to be DB controlled rather than being controlled via a next-up table in the schema since that is a more scalable approach.
Pros:
- Business Logic is not in the keys.
- Small 4-byte key (the surrogate key will most likely be an integer and SQL Server for example requires only 4 bytes to store it, if a bigint, then 8 bytes).
- Joins are very fast.
- No locking contentions because of unique constraint (this refers to the waits that get developed when two sessions are trying to insert the same unique business key) as the surrogates get generated by the DB and are cached - very scalable.
Cons:
- An additional index is needed. In SQL Server, the PK constraint will always creates a unique index, in Oracle, if an index already exists, PK creation will use that index for uniqueness enforcement (not a con in Oracle).
- Cannot be used as a search key.
- If it is database controlled, for products that support multiple databases, different implementations are needed, example: identity in SS2k, before triggers and sequences in Oracle, identity/sequence in DB2 UDB.
- Always requires a join when browsing the child table(s).
Natural Key
Pros:
- No additional Index.
- Can be used as a search key.
Cons:
- If not chosen wisely (business meaning in the key(s)), then over a period of time additions may be required to the PK and modifications to the PK can occur.
- If using strings, joins are a bit slower as compared to the int data-type joins, storage is more as well. Since storage is more, less data-values get stored per index page. Also, reading strings is a two step process in some RDBMS: one to get the actual length of the string and second to actually perform the read operation to get the value.
- Locking contentions can arise if using application driven generation mechanism for the key.
- Can’t enter a record until value is known since the value has some meaning.
Choosing Surrogate vs. Natural Keys:
There is no rule of thumb in this case. It has to be evaluated table by table:
- If we can identify an appropriate natural key that meets the three criteria for it to be a PK column, we should use it. Look-up tables and configuration tables are typically ok.
- Data-Type for the PK: the smaller the better, choose an integer or a short-character data type. It also ensures that the joins will be faster. This becomes even more important if you are going to make the PK as a clustered index since non-clustered indexes are built off the clustered index. RDBMS processes integer data values faster than the character data values because it converts characters to ASCII equivalent values before processing, which is an extra step.
Some notes and pics about install SQL Sever 2008
1- setup needs to upgrade windows installer in the current windows with i nstall DotNetFramework 3.5 with SP1
2- The Installer will install some hot fix for windows when it's needed
3- Hardware and Software Requirements for Installing SQL Server 2008 http://msdn.microsoft.com/en-us/library/ms143506.aspx
4-Security Considerations for a SQL Server Installation
http://msdn.microsoft.com/en-us/library/ms144228.aspx
5-Microsoft SQL Server 2008 Release Notes http://download.microsoft.com/download/4/9/e/49eeb41a-a769-4520-80d6-671b8ae2bd06/SQLServer2008ReleaseNotes.htm
6-System configuration checker : contain the following elements :
-Minimum operating system version
-Setup administrator
-Restart computer
-Windows managment Instrumentation(WMI) service
-Comnsistancy validation for SQL Server registry keys
-Long path names to files on SQL Server installation media
-Unsupported Sql server products
-Performance counter registry hive consistency
-Previous releases of Sql server 2008 Business Intelligence Development Studio
-Previous CTP installation
-Computer domain controller
-Microsoft .NET Application Security
-Edition WOW64 platform
-Windows PowerShell
7- Getting Started with SQL Server 2008 Failover Clustering
http://msdn.microsoft.com/en-us/library/ms189134.aspx
8- Step by step for installing SQL Server 2008




























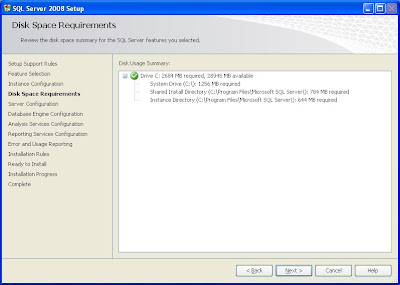

















2- The Installer will install some hot fix for windows when it's needed
3- Hardware and Software Requirements for Installing SQL Server 2008 http://msdn.microsoft.com/en-us/library/ms143506.aspx
4-Security Considerations for a SQL Server Installation
http://msdn.microsoft.com/en-us/library/ms144228.aspx
5-Microsoft SQL Server 2008 Release Notes http://download.microsoft.com/download/4/9/e/49eeb41a-a769-4520-80d6-671b8ae2bd06/SQLServer2008ReleaseNotes.htm
6-System configuration checker : contain the following elements :
-Minimum operating system version
-Setup administrator
-Restart computer
-Windows managment Instrumentation(WMI) service
-Comnsistancy validation for SQL Server registry keys
-Long path names to files on SQL Server installation media
-Unsupported Sql server products
-Performance counter registry hive consistency
-Previous releases of Sql server 2008 Business Intelligence Development Studio
-Previous CTP installation
-Computer domain controller
-Microsoft .NET Application Security
-Edition WOW64 platform
-Windows PowerShell
7- Getting Started with SQL Server 2008 Failover Clustering
http://msdn.microsoft.com/en-us/library/ms189134.aspx
8- Step by step for installing SQL Server 2008














































Wednesday, September 3, 2008
SQL Server 2005 ranking functions
SELECT SalesOrderID, SubTotal,
ROW_NUMBER() OVER(ORDER BY SubTotal DESC) AS RowNumber,
RANK() OVER(ORDER BY SubTotal DESC) AS Rank,
DENSE_RANK() OVER(ORDER BY SubTotal DESC) AS DenseRank,
NTILE(3) OVER(ORDER BY SubTotal DESC) AS NTile
FROM Sales.SalesOrderHeader
WHERE SalesOrderID IN (51885, 51886, 52031, 56410,
56411, 72585, 65101, 65814, 73976)
ORDER BY SubTotal DESC;
------------------------------------------------------------------------------------------
- ROW_NUMBER { http://msdn2.microsoft.com/en-us/library/ms186734.aspx }
- OVER clause { http://msdn2.microsoft.com/en-us/library/ms189461.aspx }
- ORDER BY clause { http://msdn2.microsoft.com/en-us/library/ms188385.aspx }
- Ranking functions { http://msdn2.microsoft.com/en-us/library/ms189798.aspx }
- What's New in SQL Server 2005 { http://www.microsoft.com/sql/prodinfo/overview/whats-new-in-sqlserver2005.mspx }
- AdventureWorks - SQL Server 2005 Samples and Sample Databases (July 2006) { http://www.microsoft.com/downloads/details.aspx?FamilyId=E719ECF7-9F46-4312-AF89-6AD8702E4E6E&displaylang=en }
- WITH common table expression { http://msdn2.microsoft.com/en-us/library/ms175972.aspx }
ROW_NUMBER() OVER(ORDER BY SubTotal DESC) AS RowNumber,
RANK() OVER(ORDER BY SubTotal DESC) AS Rank,
DENSE_RANK() OVER(ORDER BY SubTotal DESC) AS DenseRank,
NTILE(3) OVER(ORDER BY SubTotal DESC) AS NTile
FROM Sales.SalesOrderHeader
WHERE SalesOrderID IN (51885, 51886, 52031, 56410,
56411, 72585, 65101, 65814, 73976)
ORDER BY SubTotal DESC;
------------------------------------------------------------------------------------------
- ROW_NUMBER { http://msdn2.microsoft.com/en-us/library/ms186734.aspx }
- OVER clause { http://msdn2.microsoft.com/en-us/library/ms189461.aspx }
- ORDER BY clause { http://msdn2.microsoft.com/en-us/library/ms188385.aspx }
- Ranking functions { http://msdn2.microsoft.com/en-us/library/ms189798.aspx }
- What's New in SQL Server 2005 { http://www.microsoft.com/sql/prodinfo/overview/whats-new-in-sqlserver2005.mspx }
- AdventureWorks - SQL Server 2005 Samples and Sample Databases (July 2006) { http://www.microsoft.com/downloads/details.aspx?FamilyId=E719ECF7-9F46-4312-AF89-6AD8702E4E6E&displaylang=en }
- WITH common table expression { http://msdn2.microsoft.com/en-us/library/ms175972.aspx }
PIVOT Query
USE AdventureWorks;
GO
CREATE PROC MonthlyPurchaseOrder @Year int
AS
BEGIN
DECLARE @MonthlyPurchaseOrders TABLE
(VendorName nvarchar(50),
OrderMonth int,
TotalDue Money)
INSERT @MonthlyPurchaseOrders
SELECT v.Name, DATEPART(Month, OrderDate), TotalDue
FROM Purchasing.Vendor v
JOIN Purchasing.PurchaseOrderHeader poh
ON v.VendorID = poh.VendorID
WHERE v.Name like ('[c-p]%')
AND YEAR(OrderDate)=@Year
SELECT VendorName, Jan='$'+convert(varchar,[1],1),
Feb='$'+convert(varchar,[2],1), Mar='$'+convert(varchar,[3],1), Apr='$'+convert(varchar,[4],1), May ='$'+convert(varchar,[5],1),
Jun='$'+convert(varchar,[6],1), Jul='$'+convert(varchar,[7],1), Aug='$'+convert(varchar,[8],1), Sep ='$'+convert(varchar,[9],1),
Oct='$'+convert(varchar,[10],1), Nov='$'+convert(varchar,[11],1), Dec='$'+convert(varchar,[12],1)
FROM @MonthlyPurchaseOrders
PIVOT (SUM(TotalDue) FOR OrderMonth In (
[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) AS CrossTab
END
GO
EXEC MonthlyPurchaseOrder 2004
GO
GO
CREATE PROC MonthlyPurchaseOrder @Year int
AS
BEGIN
DECLARE @MonthlyPurchaseOrders TABLE
(VendorName nvarchar(50),
OrderMonth int,
TotalDue Money)
INSERT @MonthlyPurchaseOrders
SELECT v.Name, DATEPART(Month, OrderDate), TotalDue
FROM Purchasing.Vendor v
JOIN Purchasing.PurchaseOrderHeader poh
ON v.VendorID = poh.VendorID
WHERE v.Name like ('[c-p]%')
AND YEAR(OrderDate)=@Year
SELECT VendorName, Jan='$'+convert(varchar,[1],1),
Feb='$'+convert(varchar,[2],1), Mar='$'+convert(varchar,[3],1), Apr='$'+convert(varchar,[4],1), May ='$'+convert(varchar,[5],1),
Jun='$'+convert(varchar,[6],1), Jul='$'+convert(varchar,[7],1), Aug='$'+convert(varchar,[8],1), Sep ='$'+convert(varchar,[9],1),
Oct='$'+convert(varchar,[10],1), Nov='$'+convert(varchar,[11],1), Dec='$'+convert(varchar,[12],1)
FROM @MonthlyPurchaseOrders
PIVOT (SUM(TotalDue) FOR OrderMonth In (
[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) AS CrossTab
END
GO
EXEC MonthlyPurchaseOrder 2004
GO
What is CTE ?
Create Table tblCategories
(
CategoryID Int Constraint PK_tblCategories_CategoryID Primary Key,
CategoryName VarChar(100),
ParentCategoryID Int Constraint FK_tblCategories_ParentCategoryID References tblCategories(CategoryID)
)
------------------------------------------------------------------
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(1,'Languages',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(2,'Networking',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(3,'Databases',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(4,'Visual Basic',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(5,'C#',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(6,'Java',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(7,'VB.Net',4)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(8,'VB 6.0',4)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(9,'Desktop Application Development with VB.Net',7)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(10,'Web Application Development with VB.Net',7)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(11,'ActiveX Objects and VB 6.0',8)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(12,'Network Security',2)
------------------------------------------------------------------
Select * From tblCategories Where CategoryID = 1
------------------------------------------------------------------
With cteCategories
AS (
Select CategoryID,CategoryName,ParentCategoryID
From tblCategories
Where CategoryID=1
Union All
Select C.CategoryID,C.CategoryName,C.ParentCategoryID
From tblCategories As C Inner Join cteCategories As P On C.ParentCategoryID = P.CategoryID)
Select CategoryID,CategoryName,ParentCategoryID From cteCategories
(
CategoryID Int Constraint PK_tblCategories_CategoryID Primary Key,
CategoryName VarChar(100),
ParentCategoryID Int Constraint FK_tblCategories_ParentCategoryID References tblCategories(CategoryID)
)
------------------------------------------------------------------
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(1,'Languages',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(2,'Networking',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(3,'Databases',Null)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(4,'Visual Basic',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(5,'C#',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(6,'Java',1)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(7,'VB.Net',4)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(8,'VB 6.0',4)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(9,'Desktop Application Development with VB.Net',7)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(10,'Web Application Development with VB.Net',7)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(11,'ActiveX Objects and VB 6.0',8)
Insert Into tblCategories(CategoryID,CategoryName,ParentCategoryID) Values(12,'Network Security',2)
------------------------------------------------------------------
Select * From tblCategories Where CategoryID = 1
------------------------------------------------------------------
With cteCategories
AS (
Select CategoryID,CategoryName,ParentCategoryID
From tblCategories
Where CategoryID=1
Union All
Select C.CategoryID,C.CategoryName,C.ParentCategoryID
From tblCategories As C Inner Join cteCategories As P On C.ParentCategoryID = P.CategoryID)
Select CategoryID,CategoryName,ParentCategoryID From cteCategories
Subscribe to:
Posts (Atom)